-
-
Save rmcelreath/68fb40bf7a3e73bf2623e10a5973216d to your computer and use it in GitHub Desktop.
| # proxy confounder problem | |
| # cf https://twitter.com/y2silence/status/1251151157264674816 | |
| # note that I rename X1,X2 to A,B and A to X | |
| # The DAG: | |
| # X -> Y | |
| # X <- U -> Y | |
| # A <- U -> B | |
| # Can we use A and B to deconfound X->Y? | |
| # Depends upon functions relating the variables | |
| # But in linear/gaussian case, progress possible | |
| # simulate | |
| N <- 500 | |
| U <- rnorm(N) | |
| X <- rnorm(N, U ) | |
| Y <- rnorm(N, 0.5*X - U ) | |
| A <- rnorm(N, U ) | |
| B <- rnorm(N, U ) | |
| # basic regression says what? | |
| library(rethinking) | |
| precis( lm(Y ~ X) ) # confounded naturally | |
| # now full bayes model of SCM | |
| # missing data version - works remarkably well | |
| # treat each U as unobserved and assign it a parameter | |
| # rest is just the data generating model | |
| # techinical issue here is that U values can flip pos/neg across chains and then the coefficients flip pos/neg to match | |
| # but bXY seems to work fine despite this | |
| stan_code <- " | |
| data{ | |
| int N; | |
| vector[N] Y; | |
| vector[N] X; | |
| vector[N] A; | |
| vector[N] B; | |
| } | |
| parameters{ | |
| vector[4] a; | |
| real bXY; | |
| real bUX; | |
| real bUY; | |
| real bUA; | |
| real<upper=bUA> bUB; | |
| vector<lower=0>[4] sigma; | |
| vector[N] U; | |
| } | |
| model{ | |
| vector[N] muY; | |
| vector[N] muX; | |
| vector[N] muA; | |
| vector[N] muB; | |
| sigma ~ exponential( 1 ); | |
| bXY ~ normal( 0 , 1 ); | |
| bUY ~ normal( 0 , 1 ); | |
| bUX ~ normal( 0 , 1 ); | |
| bUA ~ normal( 0 , 1 ); | |
| bUB ~ normal( 0 , 1 ); | |
| a ~ normal( 0 , 1 ); | |
| U ~ normal( 0 , 1 ); | |
| // B <- U | |
| for ( i in 1:500 ) | |
| muB[i] = a[4] + bUB*U[i]; | |
| B ~ normal( muB , sigma[4] ); | |
| // A <- U | |
| for ( i in 1:500 ) | |
| muA[i] = a[3] + bUA*U[i]; | |
| A ~ normal( muA , sigma[3] ); | |
| // X <- U | |
| for ( i in 1:500 ) | |
| muX[i] = a[2] + bUX*U[i]; | |
| X ~ normal( muX , sigma[2] ); | |
| // U -> Y <- X | |
| for ( i in 1:500 ) | |
| muY[i] = a[1] + bXY*X[i] + bUY*U[i]; | |
| Y ~ normal( muY , sigma[1] ); | |
| } | |
| " | |
| dat <- list(N=N,Y=Y,X=X,A=A,B=B) | |
| ms <- stan( model_code=stan_code , data=dat , chains=1 , cores=4 , control=list(adapt_delta=0.99) , iter=4000 ) | |
| precis(ms) | |
| # covariance version marginalizing over unobserved U | |
| # need to express paths in the covariance matrix | |
| # this has pos/neg flipping issues with all the correlations with U | |
| # but again gets the X -> Y right | |
| stan_marginal <- " | |
| data{ | |
| int N; | |
| vector[N] B; | |
| vector[N] A; | |
| vector[N] Y; | |
| vector[N] X; | |
| } | |
| transformed data{ | |
| vector[4] YY[N]; | |
| for ( j in 1:N ) YY[j] = [ Y[j] , X[j] , A[j] , B[j] ]'; | |
| } | |
| parameters{ | |
| real aB; | |
| real aA; | |
| real aX; | |
| real aY; | |
| real rXY; | |
| real rUX; | |
| real rUA; | |
| real rUB; | |
| real rUY; | |
| vector<lower=0>[4] s; // std dev of each obs var | |
| } | |
| model{ | |
| vector[N] muY; | |
| matrix[4,4] SIGMA; | |
| s ~ exponential( 1 ); | |
| rXY ~ normal( 0 , 1 ); | |
| rUY ~ normal( 0 , 1 ); | |
| rUX ~ normal( 0 , 1 ); | |
| rUA ~ normal( 0 , 1 ); | |
| rUB ~ normal( 0 , 1 ); | |
| aY ~ normal( 0 , 1 ); | |
| aX ~ normal( 0 , 1 ); | |
| aA ~ normal( 0 , 1 ); | |
| aB ~ normal( 0 , 1 ); | |
| // build covariance matrix from path model | |
| for( i in 1:4 ) SIGMA[i,i] = s[i]^2; | |
| SIGMA[1,2] = rUY*rUX + rXY; // YX | |
| SIGMA[1,3] = rUY*rUA; // YA | |
| SIGMA[1,4] = rUY*rUB; // YB | |
| SIGMA[2,3] = rUX*rUA; // XA | |
| SIGMA[2,4] = rUX*rUB; // XB | |
| SIGMA[3,4] = rUA*rUB; // AB | |
| for ( i in 1:3 ) for ( j in (i+1):4 ) SIGMA[j,i] = SIGMA[i,j]; | |
| { | |
| vector[4] MU; | |
| MU = [ aY , aX , aA , aB ]'; | |
| YY ~ multi_normal( MU , SIGMA ); | |
| } | |
| } | |
| " | |
| # priors not constrained to produce positive definite covariance matrix | |
| # chains will sputter while trying to sample valid initial matrix | |
| # some inits could help with adaptation | |
| m2s <- stan( model_code=stan_marginal , data=list( N=N , Y=Y , X=X , A=A, B=B ) , chains=1, cores=4 ) | |
| precis(m2s) | |
| # blavaan | |
| # works but priors are quite different | |
| library(blavaan) | |
| m4 <- 'U =~ A + B + X + Y | |
| Y ~ X' | |
| mb <- bsem( m4, data=data.frame( Y=Y , X=X , A=A, B=B ) , bcontrol=list(cores=4) ) | |
| summary(mb) | |
| stancode( mb@external$mcmcout ) # this is unreadable |
Ben, say that I want a prior for a 4x4 covariance matrix, except the model specification requires that two off-diagonal entries must be fixed to 0 (say, sigma_12 and sigma_34). What do you do to enforce positive definite there? Something like lkj would be over the whole correlation matrix, without fixed 0s. I typically use a beta prior for each individual correlation, where beta has support on (-1,1), but I can see that possibly being problematic.
If
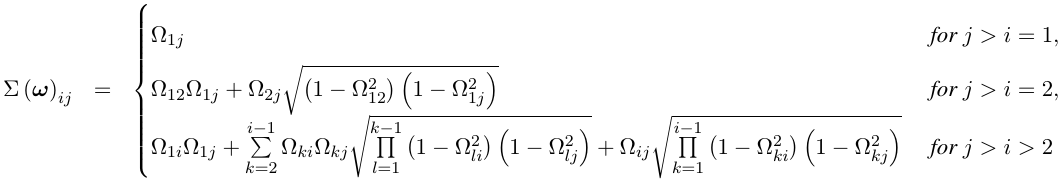
So, if
Thanks, sounds tricky but makes sense. One other clarification:
Stan continues to run but it is not drawing from the posterior distribution that it would draw from if you incorporated the truncation term.
I see two possible implications:
- The priors you think you are using are not the priors you are actually using.
- The posterior might be improper, because you are using an improper prior.
Is that right, and am I missing other implications?
I don't think (2) is an issue because if you had priors that integrated to 1 before considering that the positive definiteness constraint took a bite out of the parameter space, then whatever is left integrates to some non-constant that is less than 1. But there is also (3) that Stan might not be able to sample efficiently enough for the MCMC CLT to hold.
This is a bigger issue than the comment would lead your followers to believe. Those independent priors do not integrate to 1 over the subset of the parameter space that satisfies the positive definiteness constraint. Nor do they integrate to some constant that could, in principle, be use to renormalize without affecting what parameter values are drawn. Stan continues to run but it is not drawing from the posterior distribution that it would draw from if you incorporated the truncation term.