注意:
- かなり大雑把にまとめたので細部は間違っているかもしれません
- 結構しっかりと書かれているので並列処理周りに興味がある人はちゃんと読んでみても損はないと思います
- 導入: よくある「並列/分散の重要性が増してきている」という話
- マルチプロセッシング
- e.g. トイストーリーは100台以上のマシンを使って作った
- クライアント/サーバーコンピューティング(前者は多く、後者は少ない。役割分担)
- マルチプログラミング
- タイムシェアリングの話 (UIの応答性、マルチウィンドウ、マルチタスク、etc)
- ! 時代柄かマルチコアの話はあまり出てきていない
- 分散オブジェクト間通信機構 (ORB)
- リッチなRPC的な話?
- 遠隔実行
- Javaアプレットとか
- マルチプロセッシング
- OOPと並列/分散は相性が良くない、という話もある
- 非OOの並列性の仕組みはプロセスの概念に依るものが多い
- 独立した実行単位
- OOのオブジェクトとの類似点も多い(隠蔽された状態の保持、メソッドのメッセージパッシングモデル)
- その類似性から提案されたアクティブオブジェクトという(不十分な)概念
- プロセスでもあるオブジェクトのこと
- e.g. メインループメソッドを延々と実行するオブジェクト
- 以降はアクティブオブジェクトのダメな点
- OOPは(実行タイミングは)顧客主導であるべき
- 顧客が必要な時に必要なメソッドを呼び出せる (オブジェクトはいつでも顧客が必要なサービスを提供可能)
- 処理の実行タイミングは顧客のメソッド呼び出しに合わせる (メインループ云々ではない)
- 同期の仕組みもメソッド呼び出しに合わせたい (生産者/消費者の同期。両者のループによる解決は嫌)
- 継承と衝突する
- クラスBがクラスAから継承し、どちらもアクティブである場合はどうするのか?
- どこを実行するかを指示する専用命令を追加して、各クラスで指定することも可能だがOOP的ではない
- プロセスでもあるオブジェクトのこと
- 非OOの並列性の仕組みはプロセスの概念に依るものが多い
- 主張
- 既存の枠組みに並列/分散機能を追加するのは簡単
- むしろOOPの方が並列/分散に取り組みやすいこともある
追加で必要なのはキーワード一つだけ:
- __separate__キーワード
- オブジェクトが別__プロセッサ__に属することを指定する
- プロセッサ間の同期はメソッド呼び出しと事前条件によって実現する
- 詳しくは後述
Eiffelに平行性をもたらすために新たに必要な言語機能は一つだけ:
- __separate__キーワード
- クラスや型の宣言時にこれを指定すると、対応するオブジェクトは別の__プロセッサ__に割り当てられる
- プロセッサ: 処理の論理的な実行単位であり、最近で言えば__軽量プロセス__や__アクター__に近い
- 顧客は透過的なプロキシ(セパレートオブジェクト)経由で該当オブジェクトにアクセスする
separateキーワードの使用例:
-- クラスに指定する例 (全てのインスタンスがセパレートオブジェクトとなる)
separate class SOME_TYPE
-- 個別に指定する例
x: separate SOME_TYPE
-- メソッドの引数に使用する例
hoge(x: separate SOME_TYPE) is
do
x.fuga() -- 通常のオブジェクト同様にメソッド呼び出しが可能
x.do_command() -- 結果を必要としないなら呼び出し元はブロックしない
other_method1() -- x.do_command()実行中でも他の処理を進められる
other_method2()
result = x.query() -- 結果が必要なクエリの場合は、ブロック(同期)する (コマンド・クエリ分離と相性が良い)
end
-- 使用例
-- 注意: セパレートオブジェクトと通常のオブジェクトの暗黙的な相互変換は不可能! (型的には別物)
x: separate SOME_TYPE -- 宣言
crate x.make() -- 生成 (実体は別のプロセッサ上に生成される)
y.hoge(x) -- 引数として渡すイメージ図:
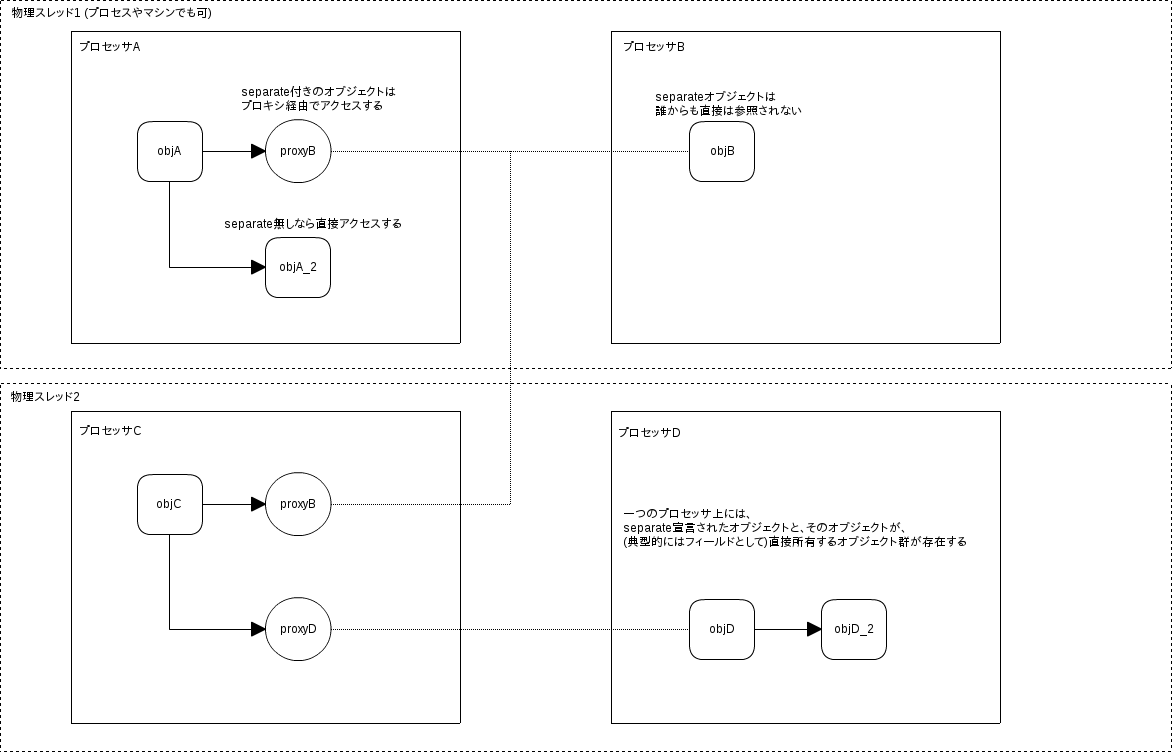
要するに:
- separateが指定されたオブジェクトは、別のプロセッサ上で実行される
- プロセッサの物理配置は別途指定する (30.4.9: 並列性制御ファイル)
- 顧客は該当オブジェクトを透過的に利用することが可能
- クエリ系のメソッド呼び出しだけブロックすることで、並行性を活用可能
- ただし、一度separateが付与された場合は、ずっとseparate付きで持ち回さなければならない
- C++風に書くなら
Actor<OriginalType>的な型になったと考えることができる (型としては別物)
- 基本は全部プロキシ経由でアクセスする
- もし実体をローカルに欲しいならディープコピーする
これでオブジェクト群を並行して実行することは可能になった:
- でもプロセッサ間での同期はどうやって取る?
- 同じオブジェクトに複数プロセッサが同時にアクセスしたら整合性が担保できないのでは?
並列処理につきものの整合性周りの問題をどう解決するか?
- 逐次処理だけなら表明(事前条件/事後条件/不変表明)の仕組みが利用可能
- 平行処理だとオブジェクトへの同時アクセスによるレースコンディションが発生して、不整合が生じてしまうのでは?
あるオブジェクトを実行(所有)するのは、一度に一つのプロセッサに制限することで解決:
- 具体的には、セパレートオブジェクトを引数で受け取ったプロセッサが、そのメソッドの実行中は所有権を有する
- 複数のプロセッサが同時に、同一のセパレートオブジェクトを引数に含むメソッド呼び出しを行った場合は、一つ以外は待機する
- これによりメソッド呼び出しの引数に含まれないセパレートオブジェクトにはアクセスできない、という制約が生まれる
- アクセスできない == そのオブジェクトのメソッドが呼び出せない (参照の持ち回しだけなら可)
class Y
feature
hoge(x: separate DB) is -- セパレートオブジェクトを引数で受け取るメソッド
do -- このメソッドの実行中は、xの所有権は呼び出し元プロセッサが有している
x.fuga()
end
main(y: Y) is
do
x: separate DB
x = DBConnectionPool.get() -- 何らかの方法でセパレートオブジェクトを取得したとする
y.hoge(x) -- 他にxをメソッド呼び出し内で使っているプロセッサがいるならブロックする
end
end- いわゆる粗粒度ロック的な荒いロックで、アトミック性(整合性)を確保
- 以下のような利点がある:
- (セパレートオブジェクト側の)メソッド実装を逐次版と変える必要がない
- 複数オブジェクトにアトミックにアクセスしたい場合も簡単 (単に複数引数を持つメソッドを用意するだけ)
- e.g. 2つのキュー間でアトミックに要素を移動する
全関数の場合は上の仕組みだけで大丈夫だが、部分関数の場合はどうするか?
-- セパレートキューを使うクラスの例
class Hoge
feature
deq(x: separete Queue) is -- キューから要素を取り出す
require
not x.empty -- 事前条件: キューは空ではいけない
do
result = x.deq()
end
is_empty(x: separete Queue) is do x.empty end
end
-- 実行部分
if not is_empty(queue) -- 逐次版ならこのチェックでOK
then
-- 平行版だとここで任意の他プロセッサがqueueを使った処理を行う可能性があるので、上のチェックが意味をなさない
result = deq(queeu)アドホックは解決方法はある:
- 例えば
dep_if_not_emptyメソッドを作る - でも、全部の組み合わせ分のメソッドを作るのは...
(セパレートオブジェクトを含む)事前条件の解釈方法を変更すれば解決:
- 逐次版: 事前条件は顧客が満たすもの
- 平行版: 事前条件が満たされるまでメソッド呼び出しを待機する
- 他のプロセッサの処理によって条件が満たされたらメソッドを実行する
一応取り上げるが、あまり面白みがないので概要だけ。
優先度がより高い顧客が存在する場合にどうするか、とか:
- 他プロセッサへの割り込みの仕組みを使う
- 割り込みを受ける側(所有者)が許可(yield)している場合にだけ別プロセッサ(挑戦者)は割り込める
- 許可していないなら、挑戦者が待機 or 例外
- 許可しているなら、所有者で例外 (後は通常の例外ハンドリングの仕組みで処理)
基本的な仕組みはかなりシンプル:
- __separate__キーワードを使ってプロセッサという論理実行単位にオブジェクトを割り当てる
- 物理配置はアプリケーションレイヤーからは切り離して、別途指定する
- オブジェクトの整合性は、一度に一つのプロセッサにしかアクセスを許可しないことで担保
- 「事前条件が満たされるまで待機」することで部分関数も既存の枠組みを崩さずに扱える
30.9でかなり丁寧にいろいろな例が紹介されている:
- 30.9.1: 食事する哲学者たち
- 30.9.2: ハードウェアの並列性を最大限活用する
- 30.9.3: ロック
- 30.9.4: コルーチン
- 30.9.5: エレベータ制御システム
- 30.9.6: 番犬(watchdog)メカニズム
- 30.9.7: バッファにアクセスする
今回は以下の2つの例を軽く取り上げる:
- 30.9.7: バッファにアクセスする
- 30.9.1: 食事する哲学者たち
この並列性の仕組みは継承と相性が良いという話。
上限付き並列キューを実装する場合の手順:
-
- 逐次キュー(BOUNDED_QUEUE)を作る
-
- BOUNDED_QUEUEを継承したセパレートキュー(BOUNDED_BUFFER)を作る
- 以下だけで実装できる
separate class BOUNDED_BUFFER[G] inherit BOUNDED_QUEUE[G] end
さらに顧客がBOUNDED_BUFFERを利用しやすくするためのクラスを用意することも可能:
- putやremove等の部分関数で待機させるためのメソッドを顧客が書かなくても良いようにする
- BUFFER_ACCESSクラス (定義は本を参照)
- 顧客は、これを継承するだけで、手軽にBOUNDED_BUFFERを利用することが可能
以下の二点が重要:
- デッドロックの回避が如何に簡単か
- 既存のロックによる手法だと落とし穴が多い
- コマンド系メソッドなら非同期に実行可能
- (あと多分継承が活用されていることも重要? PROCESSオブジェクトとか)
処理の流れ(かなり簡略版):
-
- 哲学者オブジェクトを全て別プロセッサに割り当てて起動する
- launchメソッドはブロックしないから、単純なループで実現可能
-
- 哲学者は
think; eat(left, right)のループを実行する
leftとrightはフォークを表現するセパレートオブジェクト- この2つのオブジェクトの所有権は、メソッド開始時にアトミックに取得される
- ロックの場合と違って、獲得順番を気にする必要がないのでデッドロックしない!
- (特定の哲学者が飢餓に陥ることはあるかも)
- 哲学者は
結構良く出来ている:
- 並行処理が絡むプログラミングにまつわる問題点に上手く対処している
- レースコンディションの回避
- 複雑な条件変数の排除
- 複数オブジェクトや複数メソッドの合成(アトミック呼び出し)
- 逐次板Eiffelとの親和性も高い
- 表明周りを上手く取り込んでいるのは好印象
- 逐次版実装を、ほぼそのまま流用できるのも良い
- 並列処理周りはバグが入り込みやすいので、それを排除しやすい仕組みになっているのは重要
- アクターモデルにかなり近い印象
- 実質的にプロセッサはアクターで、メソッド呼び出しはメッセージパッシング、と考えることができそう
- それをOOPの枠組みに上手く落とし込んで実現している
- 表明や型が活用できるので、ErlangやScalaのアクターよりも優れている面もありそう
以降は気になった点 (実装の工夫や機能追加等で大半は解決できそうだけど一応)
(思うままに書いていたら長くなり過ぎてしまったので、時間を見つつ適宜省略する)
気になった点(性能面):
- 平行モデルが制限されている (通常用途では悪いことではない)
- いわゆる細粒度並列化やロックフリー実装は無理
- 多くのプロセッサから同時かつ大量にアクセスされる巨大なマップとかを効率的に実装するのが難しい
- オブジェクトの所有者が常に一人、かつ、それがメソッドの全範囲に及ぶ点
- セパレートオブジェクトを実際に使用するのが、メソッド内のごく一部だとしても、所有権はメソッドを抜けるまで解放されない
- メソッドの他の部分でI/O待ちが発生したりしたらどうなるか?
- ブロックの長さを供給オブジェクト側で制御できないのが問題?
- 共有されやすいオブジェクトの場合、顧客のメソッド呼び出しが短いことを信じるしかない
- そうではないなら、無駄に他プロセッサの実行を阻害してしまう
- 分散に当てはめた場合のコスト問題
- スレッド間通信/プロセス間通信/マシン間通信、との間ではコストや速度が違いすぎる
- 同じマシン内で完結するのなら、本章くらいに通信や同期が隠蔽されている方が望ましいと思うが、マシン間通信も扱うとなると少し心配
- リモートマシン上のオブジェクトの所有権を複数プロセッサが獲得したい場合、必然的に個々の待ちが長くなる
- 何らかの理由で遅延が長くなった場合に、それが関連する全プロセッサに波及する
- アクセス前に排他確認が入る関係上、send/recvが最低一回分は増える
- プロセッサの物理配置にもかなり気を使いそう (e.g. 頻繁にやり取りするオブジェクト同士は近くに配置する)
気になった点(分散周り):
- 正しいことが前提のモデルのように見える
- 分散システムは、異常が発生するのが前提のモデルの方が相性が良い
- 予期せぬマシンダウン
- 予期せぬ遅延
- ネットワークの瞬断
- etc
- 表明をパスしたからといって、正しく動作するとは限らない
- 分散システムは、異常が発生するのが前提のモデルの方が相性が良い
- プロセッサ(オブジェクト)のダウンについても言及がなかった(と思う)
- Erlangならプロセスの死活監視は基本機能
- 供給者が死んだら顧客に例外が発生?
- 逆に顧客が死んだ場合はどうするのが適切? (ケースバイケースっぽい?)
- 事前条件によって待機を実現しているのは面白いが、ブロックはあまり分散システムとは相性が良くない
- 「A.block_call(B)」の直後に「C.get_status(B)」が実行された場合、後者にはすぐ応答が返されるのが望ましい
- そうしないとブロックが連鎖してしまう (Cを使う別のメソッドもブロックして、それを使う別の...)
- 「条件を満たしたら通知するから、それまでは別のことをやっておいて」といったモデルの方が実用的なことも多い
- 応答性を高めようとすると(事前条件による待機を避けて)結局イベント・ドリブン的な設計になってしまいそう
- 「A.block_call(B)」の直後に「C.get_status(B)」が実行された場合、後者にはすぐ応答が返されるのが望ましい
要するに:
- アクターモデルに近いけど、より安全かつ透過的な印象を受けた
- ただし、それが逆に実用上過度な制約となっていないかが心配
- 分散システムというよりは、一つのマシン上での平行システムやRPCの抽象化程度の分散、を意識しているように感じた
- 筋は悪くなさそうなので、実際に試してみたい感はある
- Eiffelから派生したSCOOPという並列志向言語があるらしい