2つの要素に対して差分を求めるとは、何が変わっていないのか、何が追加されたのか、何が削除されたのか、求める行為である。
差分を計算するために、下記3つを計算する。
- 編集距離 (levenshtein distance)
- 2つの要素の差分を数値化したもの
- LCS (Longest Common Subsequence)
- 2つの要素 X と Y の最長共通部分列
- SES (Shortest Edit Script)
- 要素 X から 要素 Y へ変換するための最短手順
これらを求めるために、下記のようなアルゴリズムがある。
- DP(動的計画法)
- MyersのO(ND)アルゴリズム
- GNU diffutils、Git等
- WuのO(NP)アルゴリズム
- subversion 等
まずは各種用語の説明を行う。
用語の説明は「LCS (Longest Common Subsequence)」、「SES (Shortest Edit Script)」、「編集距離 (levenshtein distance)」の順に説明する。
次に「DP(動的計画法)」を使ってDiffの求め方を説明し、「DP(動的計画法)」を最適化した「MyersのO(ND)アルゴリズム」のアルゴリズムを説明する。
直訳すると「最長の共通部分列」。
具体例を上げると
2つの同じ要素
- X = A, B, C, D, E, F
- Y = A, B, C, D, E, F があった場合、同じなので、 LCS = A, B, C, D, E, F となる。
2つの異なる要素が
- X = A, B, C, B, D, A, B
- Y = B, D, C, A, B, A があった場合、
- LCS = B, C, B, A
- LCS = B, D, A, B となる。
LCSは最長であれば何でもよいので、複数存在することがある。
また、元の要素に対して、連続した文字列列でなくてもよいが、文字が出現する順番は同じでなければならない。
要素 X から 要素 Y へ変換する手順。
具体例をあげると、
要素 X, Y があったとする。
- X = A, B, C, D, E, F
- Y = D, A, C, F, E, A
- LCS = A, C, F
その場合の「SES (Shortest Edit Script)」は下記のようになる
| 手順 | X | Y | LCS |
|---|---|---|---|
| A, B, C, D, E, F | D, A, C, F, E, A | A, C, F | |
| +D | D, A, B, C, D, E, F | D, A, C, F, E, A | A, C, F |
| A | D, A, B, C, D, E, F | D, A, C, F, E, A | A, C, F |
| -B | D, A, C, D, E, F | D, A, C, F, E, A | A, C, F |
| C | D, A, C, D, E, F | D, A, C, F, E, A | A, C, F |
| -D | D, A, C, E, F | D, A, C, F, E, A | A, C, F |
| -E | D, A, C, F | D, A, C, F, E, A | A, C, F |
| F | D, A, C, F | D, A, C, F, E, A | A, C, F |
| +E | D, A, C, F, E | D, A, C, F, E, A | A, C, F |
| +A | D, A, C, F, E, A | D, A, C, F, E, A | A, C, F |
要素 X から 要素 Y へ変換するための、追加と削除の階数。
下記のSESの場合、変更距離は「6」となる
| 手順 | X | Y | LCS | 編集距離 |
|---|---|---|---|---|
| A, B, C, D, E, F | D, A, C, F, E, A | A, C, F | 0 | |
| +D | D, A, B, C, D, E, F | D, A, C, F, E, A | A, C, F | 1 |
| A | D, A, B, C, D, E, F | D, A, C, F, E, A | A, C, F | 0 |
| -B | D, A, C, D, E, F | D, A, C, F, E, A | A, C, F | 1 |
| C | D, A, C, D, E, F | D, A, C, F, E, A | A, C, F | 0 |
| -D | D, A, C, E, F | D, A, C, F, E, A | A, C, F | 1 |
| -E | D, A, C, F | D, A, C, F, E, A | A, C, F | 1 |
| F | D, A, C, F | D, A, C, F, E, A | A, C, F | 0 |
| +E | D, A, C, F, E | D, A, C, F, E, A | A, C, F | 1 |
| +A | D, A, C, F, E, A | D, A, C, F, E, A | A, C, F | 1 |
「DP(動的計画法)」は、「LCS (Longest Common Subsequence)」を効率的に求める手法であるが、その過程において「編集距離 (levenshtein distance)」「SES (Shortest Edit Script)」も同時に求めることができる。
まずは、2つの要素 X, Y が下記のように定義する。
- X = A, G, C, A, T
- Y = G, A, C
要素 X, Y のマトリクスを作成し、それぞれの要素の先頭に追加し、0 で初期化する。
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Ø | A | G | C | A | T | ||
| 0 | Ø | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | G | 0 | |||||
| 2 | A | 0 | |||||
| 3 | C | 0 |
この表の算出ルールは下記のとおり。
- 要素 X のi番目と要素 Y の j番目の要素の、それぞれ一つ前の要素がベースの値となる
- どちらか一方が大きい場合は、大きい値がベースの値となる
- 要素 X のi番目と要素 Y の j番目の要素が等しい場合、ベースの値に対して 1 を加算する
上記の表に対して 要素 Y の 1文字目に対して、要素 X の各文字を処理すると、下記のようになる。
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Ø | A | G | C | A | T | ||
| 0 | Ø | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | G | 0 | 0 | 1 | 1 | 1 | 1 |
| 2 | A | 0 | |||||
| 3 | C | 0 |
要素 Y の 2文字目に対して、要素 X の各文字を処理すると、下記のようになる。
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Ø | A | G | C | A | T | ||
| 0 | Ø | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | G | 0 | 0 | 1 | 1 | 1 | 1 |
| 2 | A | 0 | 1 | 1 | 1 | 2 | 2 |
| 3 | C | 0 |
最後、 要素 Y の 3文字目に対して、要素 X の各文字を処理すると、下記のようになる。
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Ø | A | G | C | A | T | ||
| 0 | Ø | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | G | 0 | 0 | 1 | 1 | 1 | 1 |
| 2 | A | 0 | 1 | 1 | 1 | 2 | 2 |
| 3 | C | 0 | 1 | 1 | 2 | 2 | 2 |
次に、先の編集距離のマトリクスに対して、要素 X, Y の末尾から下記の手順で処理する。
- 要素 X の i 番目と、要素 Y の j 番目が等しい場合、i, j をそれぞれ減算する(マトリクスを左斜め上に進む)
- 要素 X の i 番目と、要素 Y の j 番目が等しくない場合 ** 要素 X の i-1 番目が、要素 Y の j-1 番目より大きい場合は、iを減算する(マトリクスを左に進む) ** 要素 X の i-1 番目がより、要素 Y の j-1 番目が大きい場合は、jを減算する(マトリクスを上に進む)
印をつけると下記のようになる。
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Ø | A | G | C | A | T | ||
| 0 | Ø | ||||||
| 1 | G | | | |||||
| 2 | A | \ | - | ||||
| 3 | C | \ | - | - |
印をつけた箇所で同じ直交する値が同じもののみ集めると
- LCS = A, C
となる。
更に、印を付けた箇所は
- 「-」は、要素 X → 要素 Y の変換の過程において、「削除(Delete)」されたもの
- 「|」は、要素 X → 要素 Y の変換の過程において、「追加(Add)」されたもの
- 「\」は、要素 X → 要素 Y の変換の過程において、「そのまま(Copy)」残ったもの
となる。
これらを抽出すると、「SES (Shortest Edit Script)」となる。
- 要素 X に「G」を「追加(Add)」
- 要素 X の「A」は「そのまま(Copy)」
- 要素 X から「G」を「削除(Delete)」
- 要素 X の「C」は「そのまま(Copy)」
- 要素 X から 「A」を「削除(Delete)」
- 要素 X から「T」を「削除(Delete)」
「SES (Shortest Edit Script)」 から
- 編集距離 = 4
が導き出せる。
具体例をコードにすると下記のようになる。
```python
# -*- coding: utf-8 -*-
import sys
def create_edit_graph(text1, text2):
text1_length = len(text1)
text2_length = len(text2)
edit_graph = [
[0 for j in xrange(text2_length+1)] for i in xrange(text1_length+1)]
for i in xrange(1, text1_length+1):
for j in xrange(1, text2_length+1):
if text1[i-1] == text2[j-1]:
x = 1
else:
x = 0
edit_graph[i][j] = max(
edit_graph[i-1][j-1]+x, edit_graph[i-1][j], edit_graph[i][j-1])
return edit_graph
def compute_diff(text1, text2, edit_graph):
diffs = {
'ld': 0,
'lcs': [],
'ses': [],
}
def _compute_diff(text1, text2, edit_graph):
text1_length = len(text1) if text1 is not None else 0
text2_length = len(text2) if text2 is not None else 0
if text1_length == 0 or text2_length == 0:
if text1_length > 0:
# Compute diff for subsequence.
_compute_diff(text1[:text1_length-1], text2, edit_graph)
# Count ld.
diffs['ld'] = diffs['ld'] + 1
# Add SES.
diffs['ses'].append((-1, text1[text1_length-1]))
elif text2_length > 0:
# Compute diff for subsequence.
_compute_diff(text1, text2[:text2_length-1], edit_graph)
# Count ld.
diffs['ld'] = diffs['ld'] + 1
# Add SES.
diffs['ses'].append((1, text2[text2_length-1]))
return
if (text1[text1_length-1] == text2[text2_length-1]):
# Compute diff for subsequence.
_compute_diff(
text1[:text1_length-1], text2[:text2_length-1], edit_graph)
# Add LCS.
diffs['lcs'].append(text1[text1_length-1])
# Add SES.
diffs['ses'].append((0, text1[text1_length-1]))
else:
subses = None
if edit_graph[text1_length-1][text2_length] \
>= edit_graph[text1_length][text2_length-1]:
# Compute diff for subsequence.
_compute_diff(text1[:text1_length-1], text2, edit_graph)
# Count ld.
diffs['ld'] = diffs['ld'] + 1
# Add SES.
diffs['ses'].append((-1, text1[text1_length-1]))
else:
# Compute diff for subsequence.
_compute_diff(text1, text2[:text2_length-1], edit_graph)
# Count ld.
diffs['ld'] = diffs['ld'] + 1
# Add SES.
diffs['ses'].append((1, text2[text2_length-1]))
_compute_diff(text1, text2, edit_graph)
ld = diffs['ld']
lcs = diffs['lcs']
ses = diffs['ses']
return ld, ''.join(lcs), ses
if __name__ == '__main__':
text1 = sys.argv[1]
text2 = sys.argv[2]
# Create edit graph.
edit_graph = create_edit_graph(text1, text2)
# compute diff.
ld, lcs, ses = compute_diff(text1, text2, edit_graph)
print 'LevenshteinDistance = ' + str(ld)
print 'LCS = ' + lcs
print 'SES = ' + str(ses)
```
https://ja.wikipedia.org/wiki/%E6%9C%80%E9%95%B7%E5%85%B1%E9%80%9A%E9%83%A8%E5%88%86%E5%88%97%E5%95%8F%E9%A1%8C http://d.hatena.ne.jp/naoya/20090328/1238251033
DP(動的計画法)の「LCS (Longest Common Subsequence)」「SES (Shortest Edit Script)」の算出方法の説明において、下記のようなマトリクスが出てきたが、このマトリクスを「エディットグラフ」という。
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Ø | A | G | C | A | T | ||
| 0 | Ø | ||||||
| 1 | G | | | |||||
| 2 | A | \ | - | ||||
| 3 | C | \ | - | - |
印が付いている箇所を追うと、「SES (Shortest Edit Script)」となった。
- 「-」は、要素 X → 要素 Y の変換の過程において、「削除(Delete)」されたもの
- 「|」は、要素 X → 要素 Y の変換の過程において、「追加(Add)」されたもの
- 「\」は、要素 X → 要素 Y の変換の過程において、「そのまま(Copy)」残ったもの
差分を取るアルゴリズムとは、
- 「エディットグラフ」上の最短経路を導き出すアルゴリズム
である。
それは、計算量が「O(mn)」となること、つまりは要素の大きさに比例して、計算量が多くなることである。
※ m は 要素 X の長さ、n は要素 Y の長さ。
次に説明する「MyersのO(ND)アルゴリズム」は、「エディットグラフ」上の最短経路を導き出す手順に対して最適化を行い、計算量が「DP(動的計画表)」と比較してスリムになっている。
「MyersのO(ND)アルゴリズム」の計算量は「O(ND)」である。
N は要素 X, Y の合計の長さ、D は「編集距離(levenshtein distance)」。
つまり、「編集距離(levenshtein distance)」が少なければ少ないほど高速に計算される。
「MyersのO(ND)アルゴリズム」の理解のポイントは、
- 「エディットグラフ」上で出来るだけ斜め移動を行い、終点までたどり着く経路を見つけること
である。
「エディットグラフ」上の「横移動」「縦移動」は、コストが発生しする。
そのため、「MyersのO(ND)アルゴリズム」では、できるだけコストが発生しない「斜め移動」を行う経路を最優先で処理する、といった考え方をする。
つまりは、編集距離が
- 編集距離 = 0 の時、終点までたどりつけた?
- NGの場合は、次
- 編集距離 = 1 の時、終点までたどりつけた?
- NGの場合は、次
- 編集距離 = 2 の時、終点までたどりつけた?
- NGの場合は、次 ...
と順次処理しいく。
また、「編集距離」毎に、「エディットグラフ」上で動ける距離が限定される。
下記のように「エディットグラフ」に対角線を引く。
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-96429.png
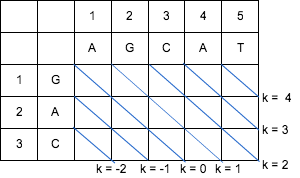{kind=link}
対角線の終点を k とすると
- k = X - Y
となる。
この時、
- 編集距離 = 0 の時は、k = 0 の対角線の範囲内のみで経路探索を行う
- 編集距離 = 1 の時は、k = 0, ±1 の対角線の範囲内のみで経路探索を行う
- 編集距離 = 2 の時は、k = 0, ±1, ±2 の対角線の範囲内のみで経路探索をおこなう ...
例えば、「編集距離 = 1」の場合「エディットグラフ」上に記すと
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-2ED5E.png
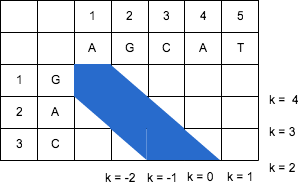{kind=link}
となる。
つまりは、編集距離 D と 対角線 k の関係は
- -D <= k <= D
となる。
要素 X, Y を下記のように定義する。
- X = A, G, C, A, T
- Y = G, A, C
「編集距離 = 0」の場合、扱える対角線は
- k = 0
となる。
「エディットグラフ」上での操作を行うと、下記のようになる。
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-2457A.png
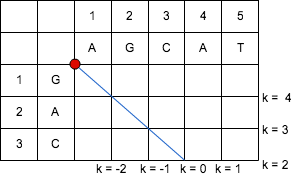{kind=link}
エディットグラフ上の終点へ至らないため、次の「編集距離 = 1」の場合を考える。
「編集距離 = 1」の場合、「エディットグラフ」上での操作を行うと、下記のようになる。
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-19343.png
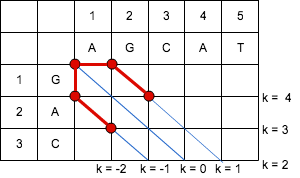{kind=link}
エディットグラフ上の終点へ至らないため、次の「編集距離 = 1」の場合を考える。
「編集距離 = 2」の場合、「エディットグラフ」上での操作を行うと、下記のようになる。
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-A906E.png
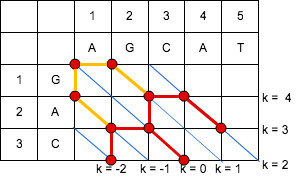{kind=link}
エディットグラフ上の終点へ至らないため、次の「編集距離 = 3」の場合を考える。
「編集距離 = 3」の場合、「エディットグラフ」上での操作を行うと、下記のようになる。
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-79D08.png
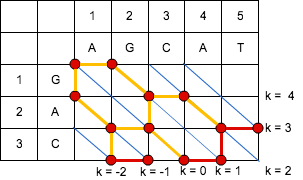{kind=link}
エディットグラフ上の終点へ至らないため、次の「編集距離 = 4」の場合を考える。
「編集距離 = 4」の場合、「エディットグラフ」上での操作を行うと、下記のようになる。
https://cacoo.com/diagrams/4hF8XidoFiOdv4CI-5DB03.png
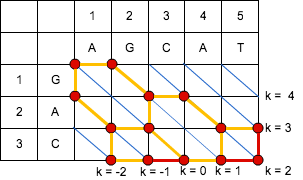{kind=link}
エディットグラフ上の終点へ至ったため、終了。
最終的な「エディットグラフ」から
- LCS = A, C
- SES
- 要素 X に「G」を「追加(Add)」
- 要素 X の「A」は「そのまま(Copy)」
- 要素 X から「G」を「削除(Delete)」
- 要素 X の「C」は「そのまま(Copy)」
- 要素 X から 「A」を「削除(Delete)」
- 要素 X から「T」を「削除(Delete)」
- 編集距離 = 4
が求まる。
具体例をコードにすると下記のようになる。
```python
# -*- coding: utf-8 -*-
import sys
def get_vk(v, index):
if str(index) in v:
return v[str(index)]
return {
'y': 0,
'tree': []
}
def exec_myers(text1, text2):
# The position of reachable y.
v = {}
# Text length.
m = len(text1) if text1 is not None else 0
n = len(text2) if text2 is not None else 0
for d in xrange(m+n+1):
for k in xrange(-(d), d+1, 2):
if k < -n or m < k:
continue
current = get_vk(v, str(k))
next_vk = None
prev_vk = None
if d != 0:
is_move_prev_vk = False
next_vk = get_vk(v, str(k+1))
prev_vk = get_vk(v, str(k-1))
if k == -d or k == -n:
is_move_prev_vk = False
elif k == d or k == m:
is_move_prev_vk = True
else:
# Move down is priorit.
if prev_vk['y'] > next_vk['y']:
is_move_prev_vk = True
else:
is_move_prev_vk = False
if is_move_prev_vk:
# Move slide.
current['y'] = prev_vk['y']
current['tree'] = list(prev_vk['tree'])
current['tree'].append(-1)
else:
# Move Down.
current['y'] = next_vk['y'] + 1
current['tree'] = list(next_vk['tree'])
current['tree'].append(1)
y = current['y']
x = k + y
while x < m and y < n and text1[x] == text2[y]:
current['tree'].append(0)
x = x + 1
y = y + 1
current['y'] = y
if x >= m and y >= n:
return current['tree']
v[str(k)] = current
return None
def compute_diff(text1, text2):
diffs = {
'ld': 0,
'lcs': [],
'ses': [],
}
# Run myers algorithm.
actions = exec_myers(text1, text2)
# Format.
text1_index = 0
text2_index = 0
if actions:
for action in actions:
if action == 0:
# Copy
diffs['ses'].append((action, text1[text1_index]))
diffs['lcs'].append(text1[text1_index])
text1_index = text1_index + 1
text2_index = text2_index + 1
elif action == 1:
# Add.
diffs['ses'].append((action, text2[text2_index]))
diffs['ld'] = diffs['ld'] + 1
text2_index = text2_index + 1
elif action == -1:
# Delete.
diffs['ses'].append((action, text1[text1_index]))
diffs['ld'] = diffs['ld'] + 1
text1_index = text1_index + 1
return diffs['ld'], ''.join(diffs['lcs']), diffs['ses']
if __name__ == '__main__':
text1 = sys.argv[1]
text2 = sys.argv[2]
# Compute diff.
ld, lcs, ses = compute_diff(text1, text2)
print 'LevenshteinDistance = ' + str(ld)
print 'LCS = ' + lcs
print 'SES = ' + str(ses)
```
http://www.slideshare.net/matuura/diff-3119288 http://constellation.hatenablog.com/entry/20091021/1256112978
「MyersのO(ND)アルゴリズム」の改良版。
改良したアルゴリズムでは、「エディットグラフ」上の始点・終点の両方から経路探索を行い、「エディットグラフ」上で重なり合う枝※を見つけ、存在する場合は比較要素を分割して、分割した比較要素で経路探索を繰り返し行う。
※ myersの論文では、重なり合う枝のことを middle snake と表現している。
https://cacoo.com/diagrams/seuTJYOLVmgreyIs-1623D.png
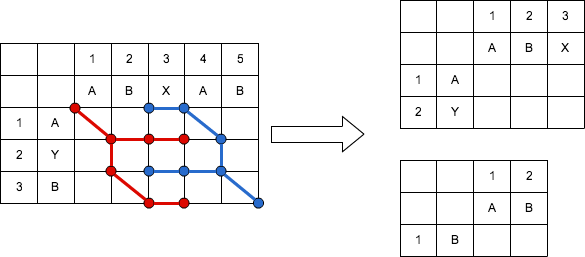{kind=link}
ほとんどの場合、50%程パフォーマンスが向上するらしい。
```python
# -*- coding: utf-8 -*-
import sys
def binary_seach_middle_snake(text1, text2, x, y):
text1a = text1[:x]
text2a = text2[:y]
text1b = text1[x:]
text2b = text2[y:]
# Compute both diffs serially.
diffs = myers(text1a, text2a)
diffsb = myers(text1b, text2b)
return diffs + diffsb
def myers_middle_snake(text1, text2):
# Cache the text lengths to prevent multiple calls.
text1_length = len(text1)
text2_length = len(text2)
max_d = (text1_length + text2_length + 1) // 2
v_offset = max_d
v_length = 2 * max_d
v1 = [-1] * v_length
v1[v_offset + 1] = 0
v2 = v1[:]
delta = text1_length - text2_length
# If the total number of characters is odd, then the front path will
# collide with the reverse path.
front = (delta % 2 != 0)
# Offsets for start and end of k loop.
# Prevents mapping of space beyond the grid.
k1start = 0
k1end = 0
k2start = 0
k2end = 0
for d in xrange(max_d):
# Walk the front path one step.
for k1 in xrange(-d + k1start, d + 1 - k1end, 2):
k1_offset = v_offset + k1
if k1 == -d or (k1 != d and v1[k1_offset - 1] < v1[k1_offset + 1]):
x1 = v1[k1_offset + 1]
else:
x1 = v1[k1_offset - 1] + 1
y1 = x1 - k1
while (x1 < text1_length and y1 < text2_length and
text1[x1] == text2[y1]):
x1 += 1
y1 += 1
v1[k1_offset] = x1
if x1 > text1_length:
# Ran off the right of the graph.
k1end += 2
elif y1 > text2_length:
# Ran off the bottom of the graph.
k1start += 2
elif front:
k2_offset = v_offset + delta - k1
if k2_offset >= 0 and k2_offset < v_length and v2[k2_offset] != -1:
# Mirror x2 onto top-left coordinate system.
x2 = text1_length - v2[k2_offset]
if x1 >= x2:
# Overlap detected.
return binary_seach_middle_snake(text1, text2, x1, y1)
# Walk the reverse path one step.
for k2 in xrange(-d + k2start, d + 1 - k2end, 2):
k2_offset = v_offset + k2
if k2 == -d or (k2 != d and v2[k2_offset - 1] < v2[k2_offset + 1]):
x2 = v2[k2_offset + 1]
else:
x2 = v2[k2_offset - 1] + 1
y2 = x2 - k2
while (x2 < text1_length and y2 < text2_length and
text1[-x2 - 1] == text2[-y2 - 1]):
x2 += 1
y2 += 1
v2[k2_offset] = x2
if x2 > text1_length:
# Ran off the left of the graph.
k2end += 2
elif y2 > text2_length:
# Ran off the top of the graph.
k2start += 2
elif not front:
k1_offset = v_offset + delta - k2
if k1_offset >= 0 and k1_offset < v_length and v1[k1_offset] != -1:
x1 = v1[k1_offset]
y1 = v_offset + x1 - k1_offset
# Mirror x2 onto top-left coordinate system.
x2 = text1_length - x2
if x1 >= x2:
# Overlap detected.
return binary_seach_middle_snake(text1, text2, x1, y1)
# Diff took too long and hit the deadline or
# number of diffs equals number of characters, no commonality at all.
return [(-1, text1), (1, text2), ]
def myers(text1, text2):
if not text1 and not text2:
return []
if not text1:
return [(1, text2)]
if not text2:
return [(-1, text1)]
if len(text1) == 1 and len(text2) == 1:
return [(1, text2), (-1, text1)] if text1 != text2 else [(0, text1)]
if len(text1) > len(text2):
(longtext, shorttext) = (text1, text2)
else:
(shorttext, longtext) = (text1, text2)
i = longtext.find(shorttext)
if i != -1:
diffs = [
(1, longtext[:i]),
(0, shorttext),
(1, longtext[i + len(shorttext):]),
]
# Swap insertions for deletions if diff is reversed.
if len(text1) > len(text2):
diffs[0] = (-1, diffs[0][1])
diffs[2] = (-1, diffs[2][1])
if not diffs[2][1]:
del diffs[2]
return diffs
if len(shorttext) == 1:
return [(-1, text1), (1, text2)]
return myers_middle_snake(text1, text2)
def compute_diff(text1, text2):
diffs = {
'ld': 0,
'lcs': [],
'ses': [],
}
# Run myers algorithm.
diffs['ses'] = myers(text1, text2)
# Format.
text1_index = 0
text2_index = 0
for action, s in diffs['ses']:
if action == 0:
# Copy
diffs['lcs'].append(text1[text1_index])
text1_index = text1_index + 1
text2_index = text2_index + 1
elif action == 1:
# Add.
diffs['ld'] = diffs['ld'] + 1
text2_index = text2_index + 1
elif action == -1:
# Delete.
diffs['ld'] = diffs['ld'] + 1
text1_index = text1_index + 1
return diffs['ld'], ''.join(diffs['lcs']), diffs['ses']
if __name__ == '__main__':
text1 = sys.argv[1]
text2 = sys.argv[2]
# Compute diff.
ld, lcs, ses = compute_diff(text1, text2)
print 'LevenshteinDistance = ' + str(ld)
print 'LCS = ' + lcs
print 'SES = ' + str(ses)
```