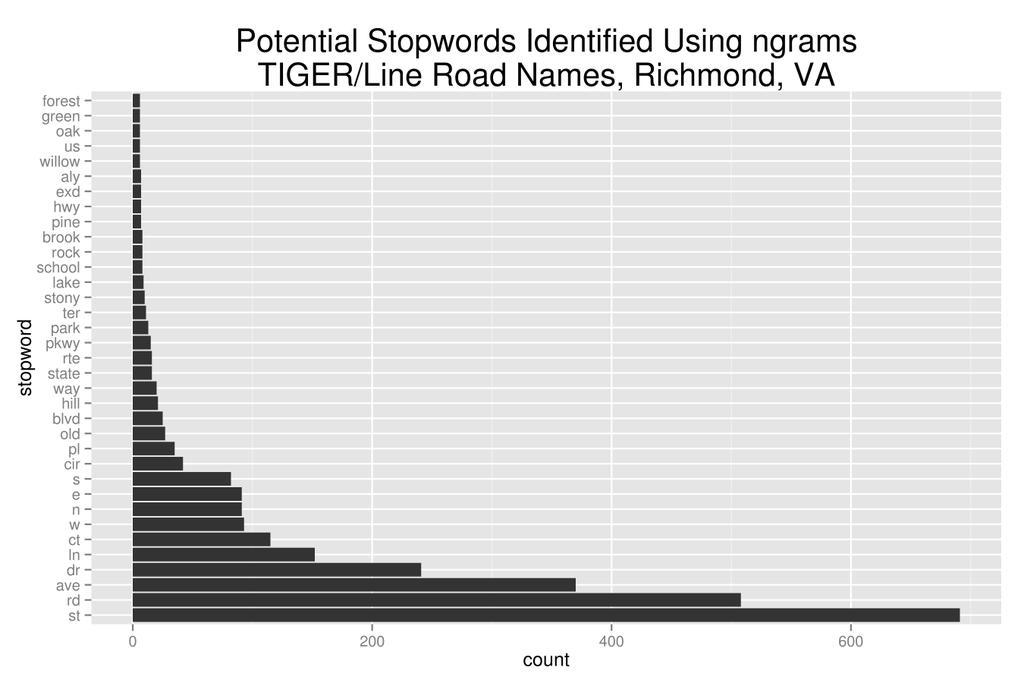
#identifying stopwords using ngrams and vowels
- we have: street names in Richmond, VA
- we want to: match street names to Confederate generals and Civil Rights leaders
- first we must: remove small pesky elements of names that are irrelevant to the match
# name of input plain text file - in this case, list of TIGER/Line road names in Richmond, VA
in=tiger.csv
# set max string length to be considered a stopword
n=6
# identify unigrams from the input file
ngrams $in 1 |\
# get two column TSV of frequency, unigram
sortfreq |\
# strip out header
sed '1d' |\
# take any string <= length *n*, OR that has no vowels
awk "{if(length(\$2)<= $n || \$2 ~ /^[^aeiou]*$/ )print \$0}"|\
# get top 40 most frequent
head -n 40 |\
# now use ggplot to make a graph of our results
# the graph is 6in in height and 9in wide, with size 20 title font!
plotbars stopword count "Potential Stopwords Identified Using ngrams\nTIGER/Line Road Names, Richmond, VA" 20 6 9