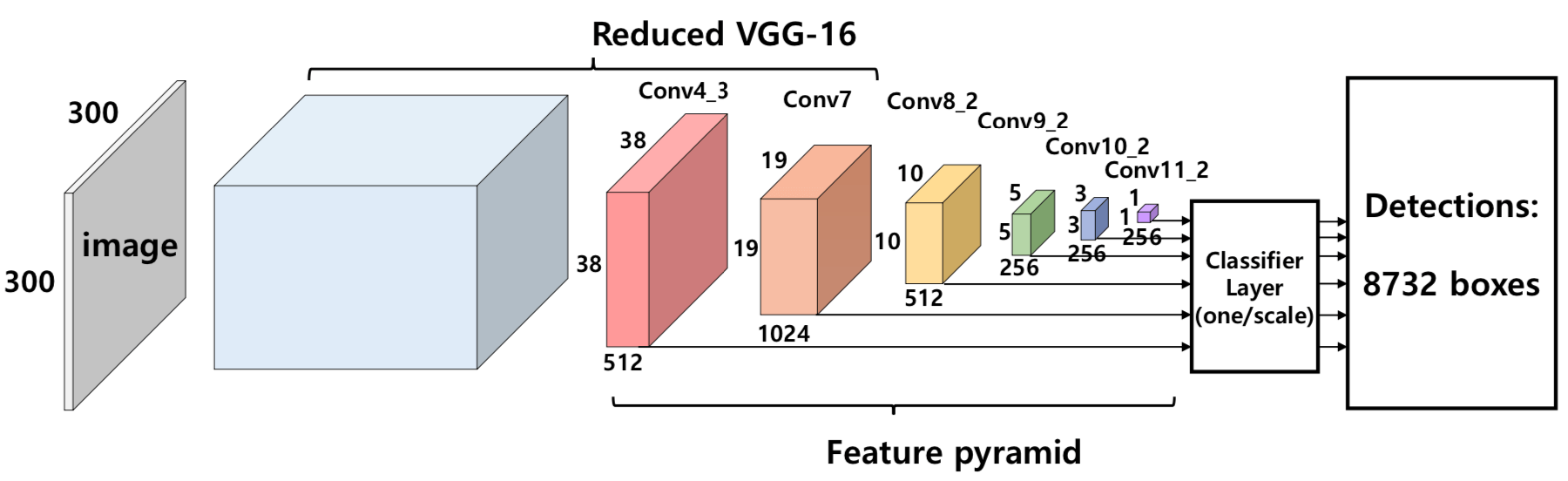
Enhancement of SSD by concatenating feature maps for object detection
SSD 的缺点:
- each layer in the feature pyramid is used independently 由此导致了 the same object can be detected in multiple scales
- 具体说明: a certain position of a feature map in a lower layer (say, Conv4-3) is activated. This information can affect entire scales up to the the last layer (Conv11-2), which means that the relevant positions in the higher layers have a good chance to be also activated 但是 SSD 目前没有这种约束
- small objects are not detected well
相应的该怎么改善 SSD
- 针对缺点 1: considering the relationship between layers in the feature pyramid
- 针对缺点 2: 就是提升特征的 abstract representation 能力, 作者用的是增加 Feature pyramid 中的 channel 数 (Feature pyramid, 不是 base network, 具体两者的差别见下面这张 SSD 的结构图)
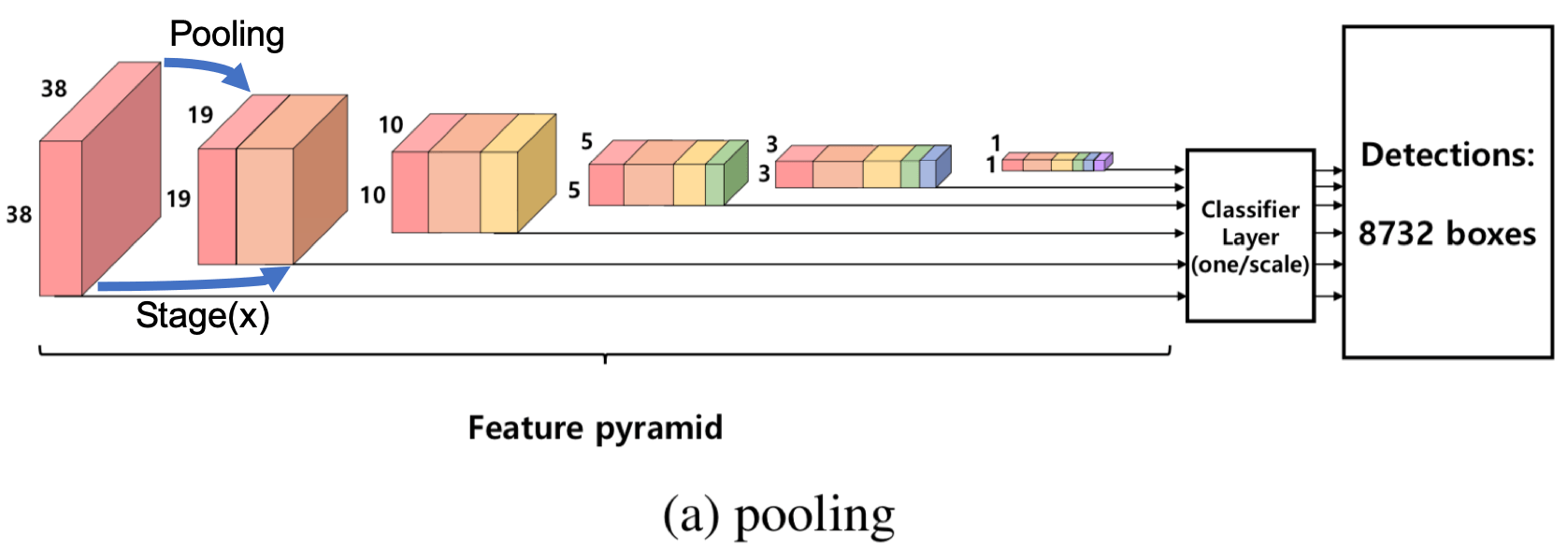
- 通过 pooling: feature maps in the lower layers are concatenated to those of the upper layers through pooling 这是最简单易懂的, 就是把低层的特征 pooling 后直接与 高层的特征堆在一起
- 通过 deconvolution: 文章中说的是 concatenating the feature maps of the upper layers to the lower layer features through deconvolution or upsampling, 我觉得这个应该就跟 DSSD 差不多的结构, 只不过 DSSD 是 element-wise sum 或者 element-wise production, 而这里应该是 concat, 这也就是 U-Net 吧.
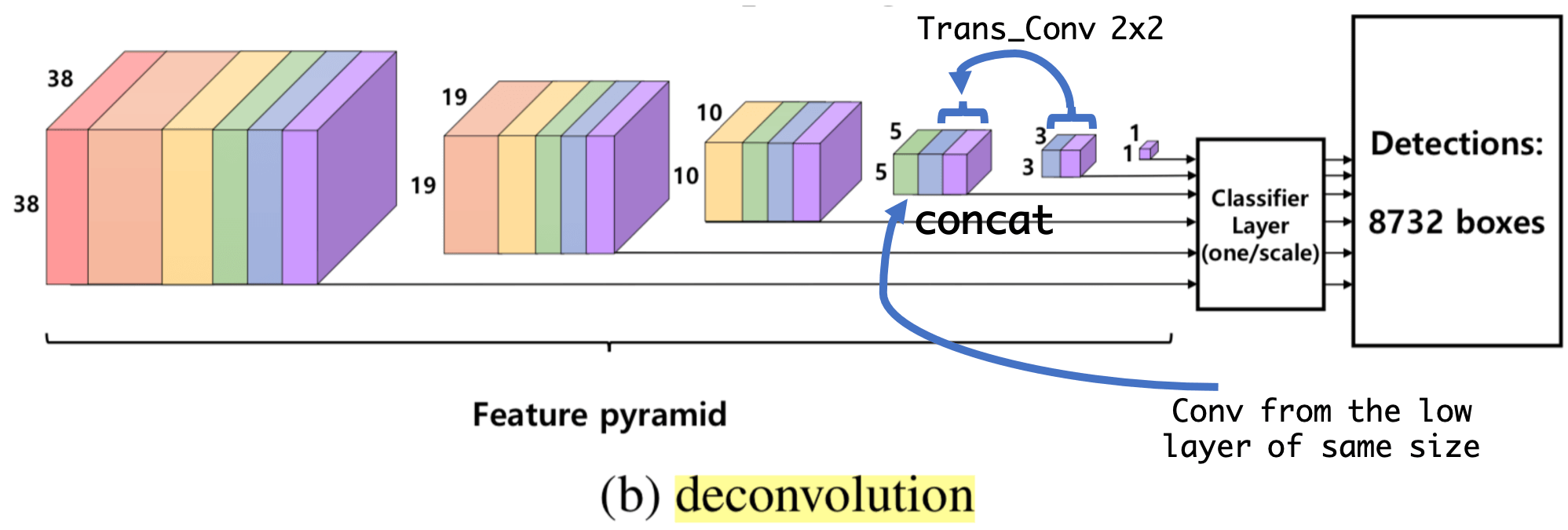
问题: 作者怎么保证 本文方法不会出现不同 layer 不预测同一目标的问题
本文提出的 Rainbow concatenation 就是 pooling and deconvolution are performed simultaneously to create feature maps with an explicit relationship between different layers