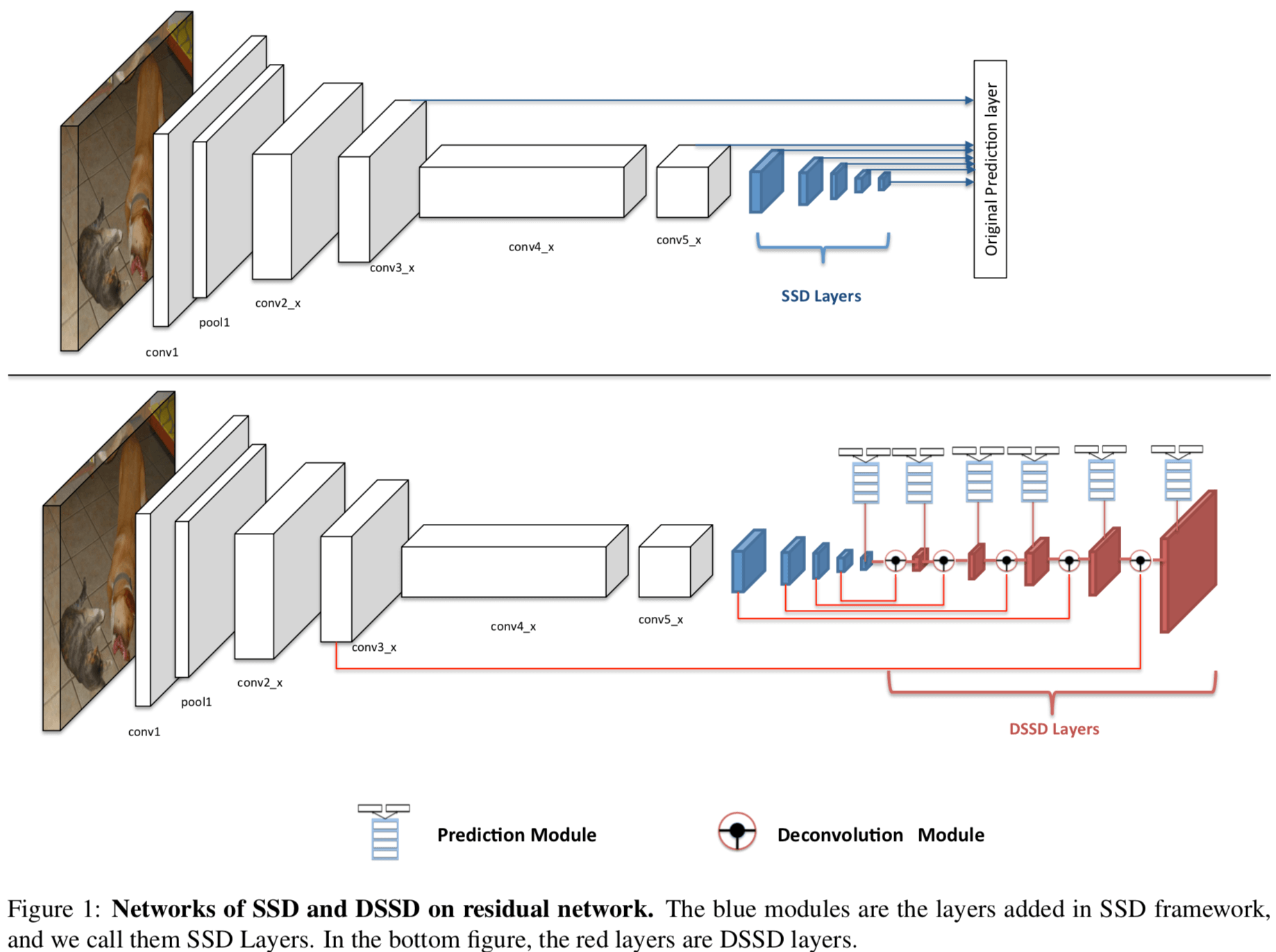
augment SSD+Residual-101 with deconvolution layers to introduce additional large-scale context in object detection and improve accuracy, especially for small objects
improve detection accuracy 的方式
- exploiting multiple layers within a ConvNet
- 方式 1: combine feature maps from different layers of a ConvNet and use the combined feature map to do prediction
- 代表: ION 和 HyperNet
- 优点: features from different levels of abstraction of the input image, the pooled feature is more descriptive and is better suitable for localization and classification
- 缺点: not only increases the memory footprint of a model significantly but also decreases the speed of the model
- 方式 2: uses different layers within a ConvNet to predict objects of different scales
- 代表: SSD
- 方式 1: combine feature maps from different layers of a ConvNet and use the combined feature map to do prediction
in order to detect small objects well, these methods need to use some information from shallow layers with small re- ceptive fields and dense feature maps,
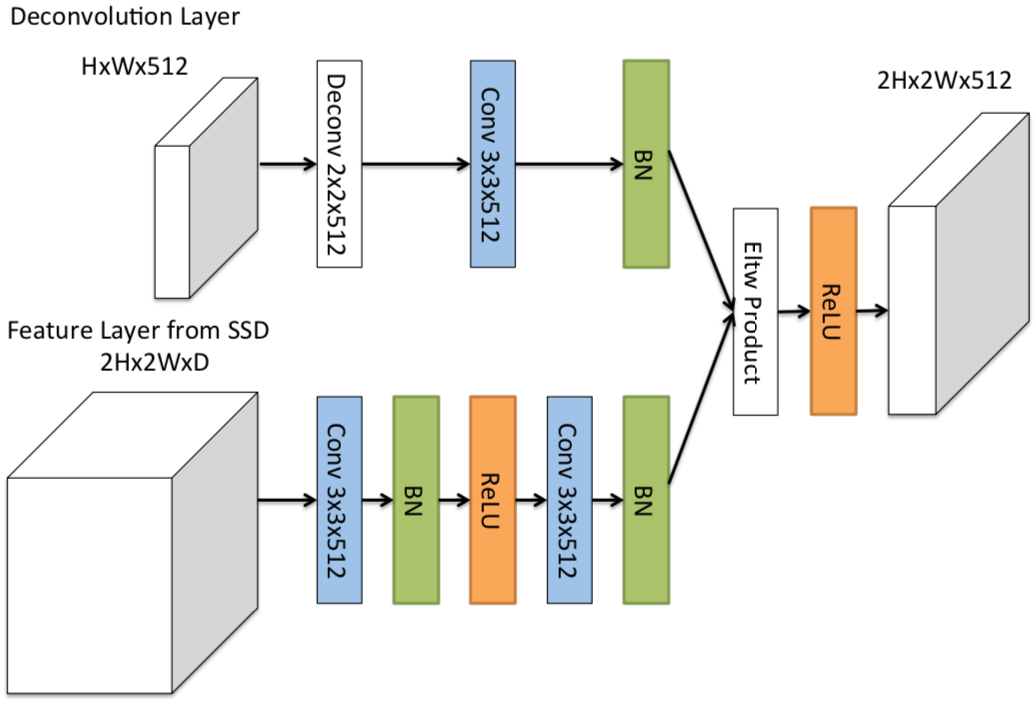
DSSD 用 deconvolution layers 的目的就在于: By using deconvolution layers and skip connections, we can inject more se- mantic information in dense (deconvolution) feature maps, which in turn helps predict small objects.
本文在 SSD 之上的改进
- Backbone: 用 Residual-101 代替 VGG
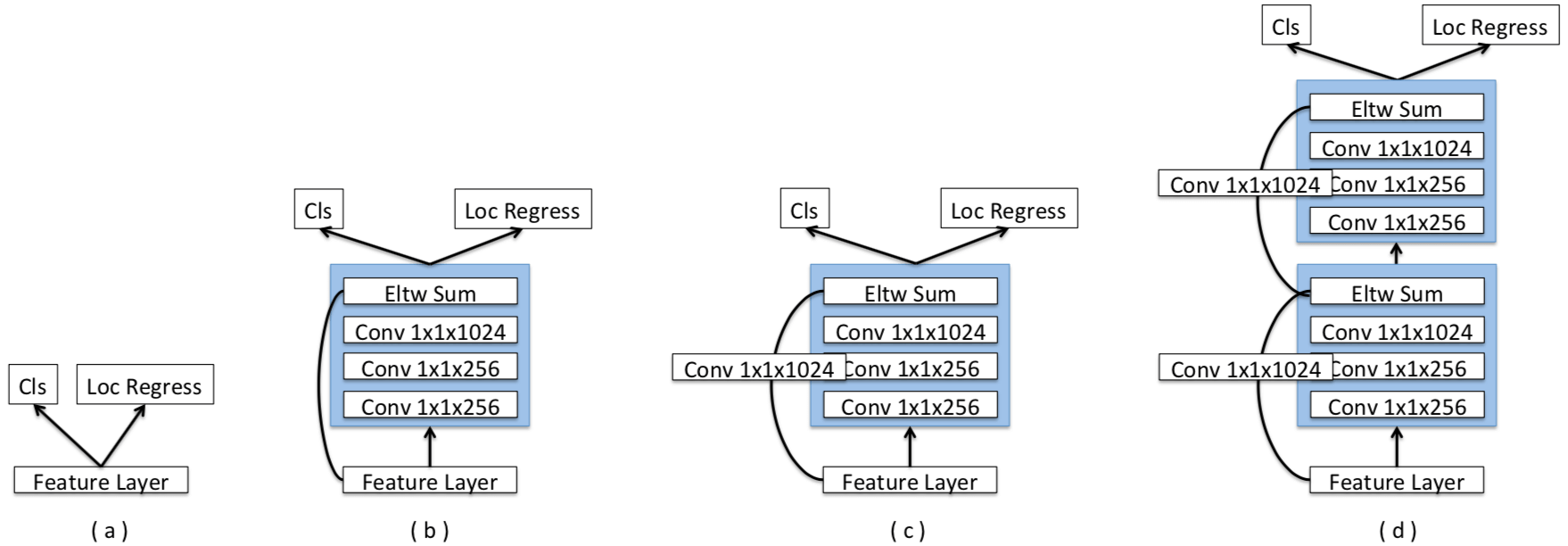
- Prediction Module: add one residual block for each prediction layer (具体见下图)
- 特征 Exploiting multiple layers: 引入 a deconvolution module 具体如下图所示 element-wise product 这是不是 Attention ?