- aggregate/tag all useful language learning educational material on the web
- create enough output JSON docs to:
- offer pre-made high quality content on any topic
- serve as a raw data for training generative ML models
- minimize editorial review step as much as possible
Each input typically has a "media-type" associated with it (video, audio, html, pdf, etc). Every media type has an "extractor program" that is designed to extract the language data from it. E.g:
- video media-type uses youtube-dl to extract subtitles.
- image media-type uses Tesseract to extract text from images.
- HTML media-type uses Scrapy, Beautiful Soup, or just the Python Requests library
- Webpage, articles, blogs [mvp]
- Video (Youtube) [mvp]
- Audio (soundcloud, podcasts, Spotify)
- Files (pdf, docx, etc) [mvp]
- Images (infographics, etc)
- Games (typically a sub-type of webpage)
- App (no extraction on these, we just track them)
- APIs (dictionary api, news apis, etc)
- direct submissions to external resources table [mvp]
- student/teacher internal message (e.g. our session recap) [mvp]
- FC Webscrapers (e.g. our sports scraper, PRAW) [mvp]
- CRON jobs to 3rd party data providers like pushshift.io and wikipedia
- Authenticated API endpoint; FC staff CLI that posts to said endpoint
- 3rd party APIs like newscatcher.api
- Activity JSON Structure [mvp]
- LMS output types like SCORM
- PDF & Google Docs
section on how processing works
url added to external-resources table
url submitted to processing queue
urls content-type is identified (youtube video)
"video" media-type tag is added
youtube subtitle extractor loads and extracts raw text
language-identifier runs on raw text and adds "english" tag
Verb-Tense analyzer runs on raw text
CEFR Level Tagger runs on raw text (adds "A1" tag)
Topic Detecter runs on raw text (adds "food" tag w/ confidence)
external-resource is flagged for manual review.
Admin reviews, makes adjustments and hits "approve" button
resource is indexed for search (Postgres, later ElasticSearch)
STEP 1:
User or Admin defines desired lesson parameters
- target language
- taught in language
- level
- media type
- activity type
- pedagogical type
- communicative objective
- grammar objective
- language specific objective
- topic
STEP 2:
The parameters selected above filter applicable source-materials
STEP 3:
(optional) User selects/discards recommended source materials
STEP 4:
materials are processed into activity JSON format
Supplementary 3rd party content is added (if applicable)
- presaved idioms, vocab, phrases by topic
- common errors (e.g. mult-choice preposition distractors)
- wikipedia lookups (e.g. named-entity supplements)
- Generative models run, e.g. question prompts (if applicable)
STEP 5
Lesson is auto-generated from the Step-4 output JSON.
The output is the result of the Transform step of the pipeline. Output is often synonymous with the final product from a pure data perspective. E.g. the Activity JSON output is a pure data representation of a learning activity.
- Activity JSON Structure [mvp]
- LMS output types like SCORM
- PDF & Google Docs
- 3rd Party Integrations (e.g. typeform, quizlet)
- ML Training Data
- fill-in-blank
- multipe-choice
- true-false
- matching
- short-answer
- video
- audio
- interactive-table
- flash-cards
- write-in-columns (depricated)
- roulette wheel
- dialog
Lessons are a collection of one or more activity. You can think of it as the input JS Object you would put into a top level React component that generates a language lesson. The High level component structure is:
Course
Unit
Lesson
Section
Activity
See Definitions Doc for details
- Course: groups a collection of units (analagous to a book grouping chapters)
- Unit: a series of lessons usually grouped around a topic (like a chapter)
- Lesson: content covered in a teacher/student meeting (like a page)
- Section: a collection of 1 or more activities (like a section of a page)
- Activity: the actual interactive widget (see list of activity-types above)
Data-lake architecture will be no more than a simple S3 bucket to start with. See Appendix for an example of a ML model development pipeline that would eventually be used to deploy nodes into the Data Pipeline discussed in this section.
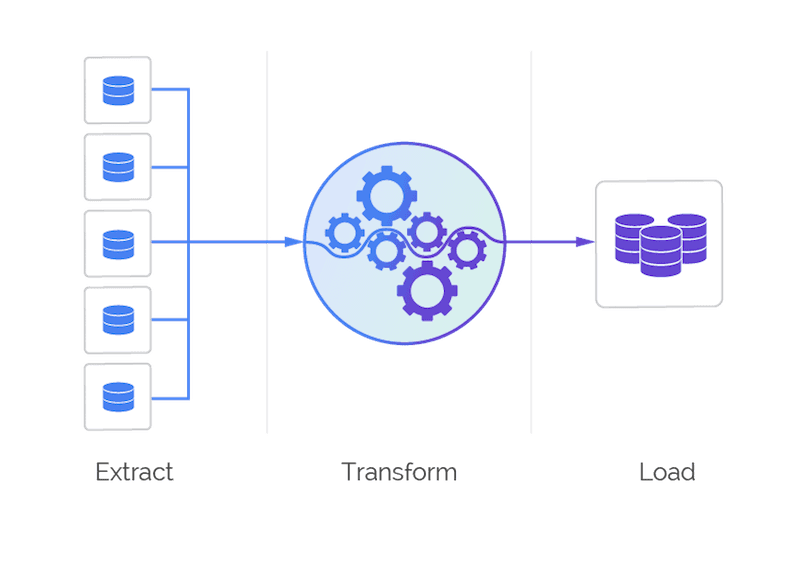
Extract => S3
Transform => The Data Pipeline
Load => Fluent City Postgres DB
To start with we are going to build a "dumb version" of a pipeline. Example of types of solutions in the realm of consideration are:
- AWS Data Pipeline
- AWS Lambda scripts that trigger when objects are added to an S3 bucket
- Extraction: extracts data from an input media-type (url, pdf, video, etc)
- Classification: loads pickle file or model and runs classification
- Supplementation: consults stored data in FC DB or 3rd party services
- Transformation: pure python code that transforms data from one form to another
Practically speaking nodes will likely take one of the following common forms:
- pure python program (e.g. AWS lambda friendly)
- SpaCy custom component. E.g. the Fluent City Verb Phrase Finder
- loading a Python Pickle using Scikit-learn code (e.g. see basic example)
- large external model (e.g. Hugging face models like BERT and GPT-2)
- non destructive data extraction (keep raw data)
- extractors/transformers include version tags
- ability to quickly load new components to processing
- possibly DAG style processing pipeline (eventually)
- versioned schema validation
- Heroku limitations (e.g. slugsize)
- how to provision pipeline processing steps that require large language models
- how to switch between language models in SpaCy pipeline nodes
- NLP-Progress Good overview of state of the art NLP techniques
- HuggingFace Source of many of the transformer models we use.
- SpaCy Our NLP library of choice
- SpaCy Models The core language models we use
NOTE: these are not the real schemas, they just illustrate the basic notion that different "activity types" have different JSON structures.
{
'meta': {
'language': 'en',
'activity_type': 'fill-in-blank',
'activity_name': 'verb',
'time_limit': 0,
'duration': 0,
},
'results': {
'score': 0,
'grade': 'A',
'total': 1,
'questions': {
'1': {
'completed': True,
'attempts': 1,
'value': 0,
'points': 0,
}
}
},
'history': [
{
'action': 'submit answer',
'timestamp': '00:00:00',
'details': {
'question_id': 1,
'answer_id': [1],
},
}
],
'text': "\nFar out in the uncharted backwaters of the unfashionable end of the western spiral arm of the Galaxy lies a small unregarded yellow sun.\n\nOrbiting this at a distance of roughly ninety-two million miles is an utterly insignificant little blue green planet whose ape- descended life forms are so amazingly primitive that they still think digital watches are a pretty neat idea.\n\nThis planet has - or rather had - a problem, which was this: most of the people living on it were unhappy for pretty much of the time. Many solutions were suggested for this problem, but most of these were largely concerned with the movements of small green pieces of paper, which is odd because on the whole it wasn't the small green pieces of paper that were unhappy.\n\nAnd so the problem remained; lots of the people were mean, and most of them were miserable, even the ones with digital watches.\n",
'ents': [
{'start': 95, 'end': 101, 'label': 'ORG'},
{'start': 170, 'end': 202, 'label': 'QUANTITY'}
],
'sents': [
{'start': 0, 'end': 139},
{'start': 139, 'end': 378},
{'start': 378, 'end': 512},
{'start': 513, 'end': 749},
{'start': 749, 'end': 877}
],
'tokens': [
...
],
'questions': [
{
'id': 1,
'label': 'a',
'start': 0,
'end': 0,
'sent_start': 0,
'sent_end': 25,
'type': 'fill-in-blank',
'title': 'English word for inu?',
'description': '',
'required': True,
'evaluation_type': 'iregex',
'answer': '(dog|canine|hound)',
},
],
}{
'meta': {
'language': 'en',
'activity_type': 'multipe-choice',
'activity_name': 'name',
},
'questions': [
{
'id': 1,
'label': 'A',
'start': 0,
'end': 5,
'sent_start': 0,
'sent_end': 25,
'type': 'multiple-choice',
'title': 'which one?',
'description': 'pick the best answer.',
'required': True,
'evaluation_type': 'exact',
# the possible answers to the question
'answer': {
'choices': [
{'id': 1, 'value': 'answer 1'},
{'id': 2, 'value': 'answer 2'},
{'id': 3, 'value': 'answer 3'},
],
# ids or id combinations that must be True.
# the following has two correct answers:
# id 1 alone or ids 2 and 3 together.
'answer_key': [1, [2, 3]],
},
# (optional) feedback to provide on success/failure.
# this will often be dynamically generated via a function
'feedback': {
'correct': 'good job',
'incorrect': 'shitty job',
},
},
],
}This section is included to give context to the pipeline. I.e, it would be ideal that whatever "pipeline" we do build stays open to an future integration with an ML CI workflow.
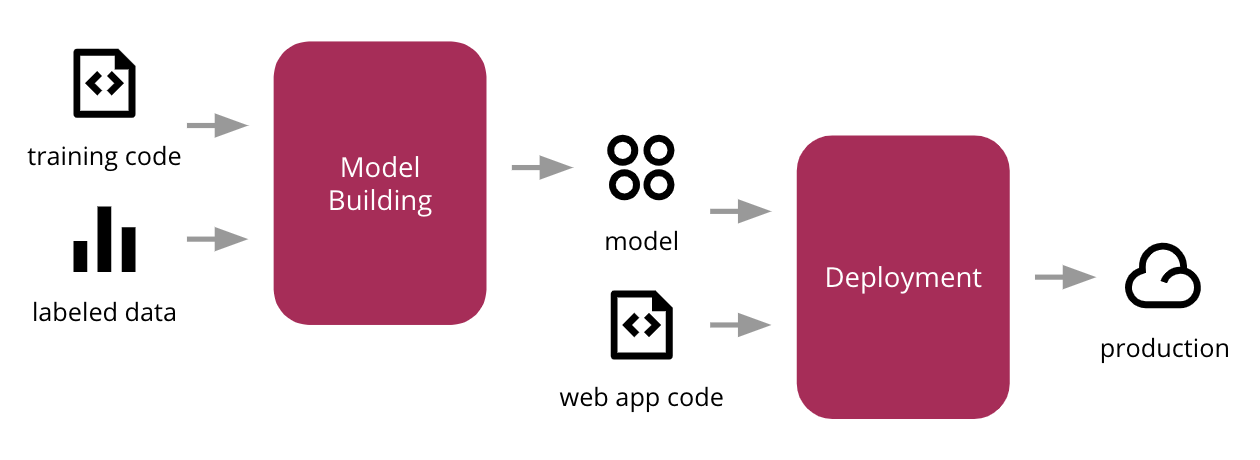
General outline of ML development process
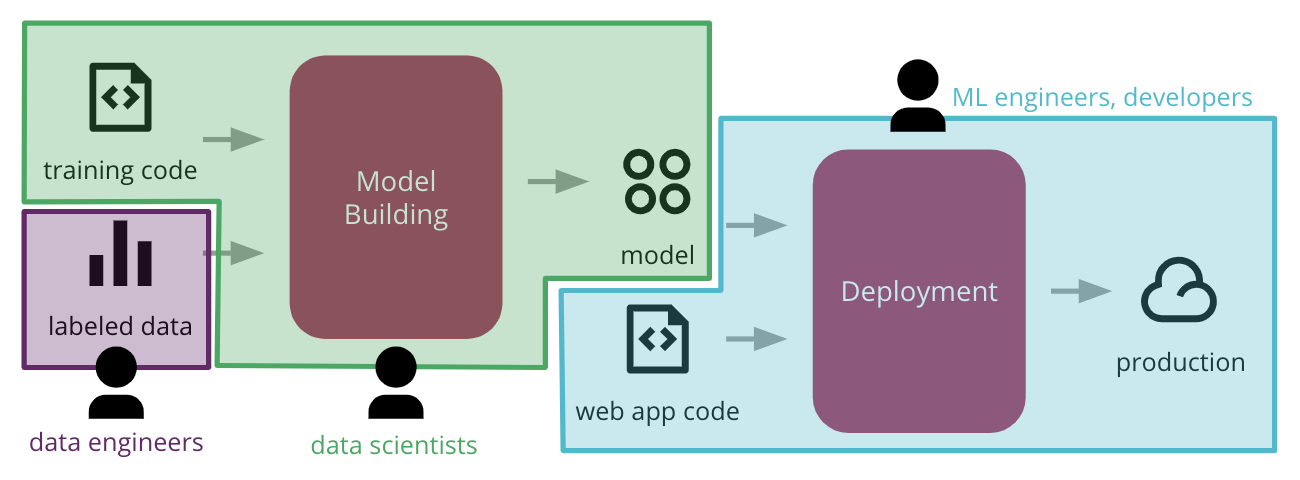
Example of aforementioned pipeline divided by responsibility
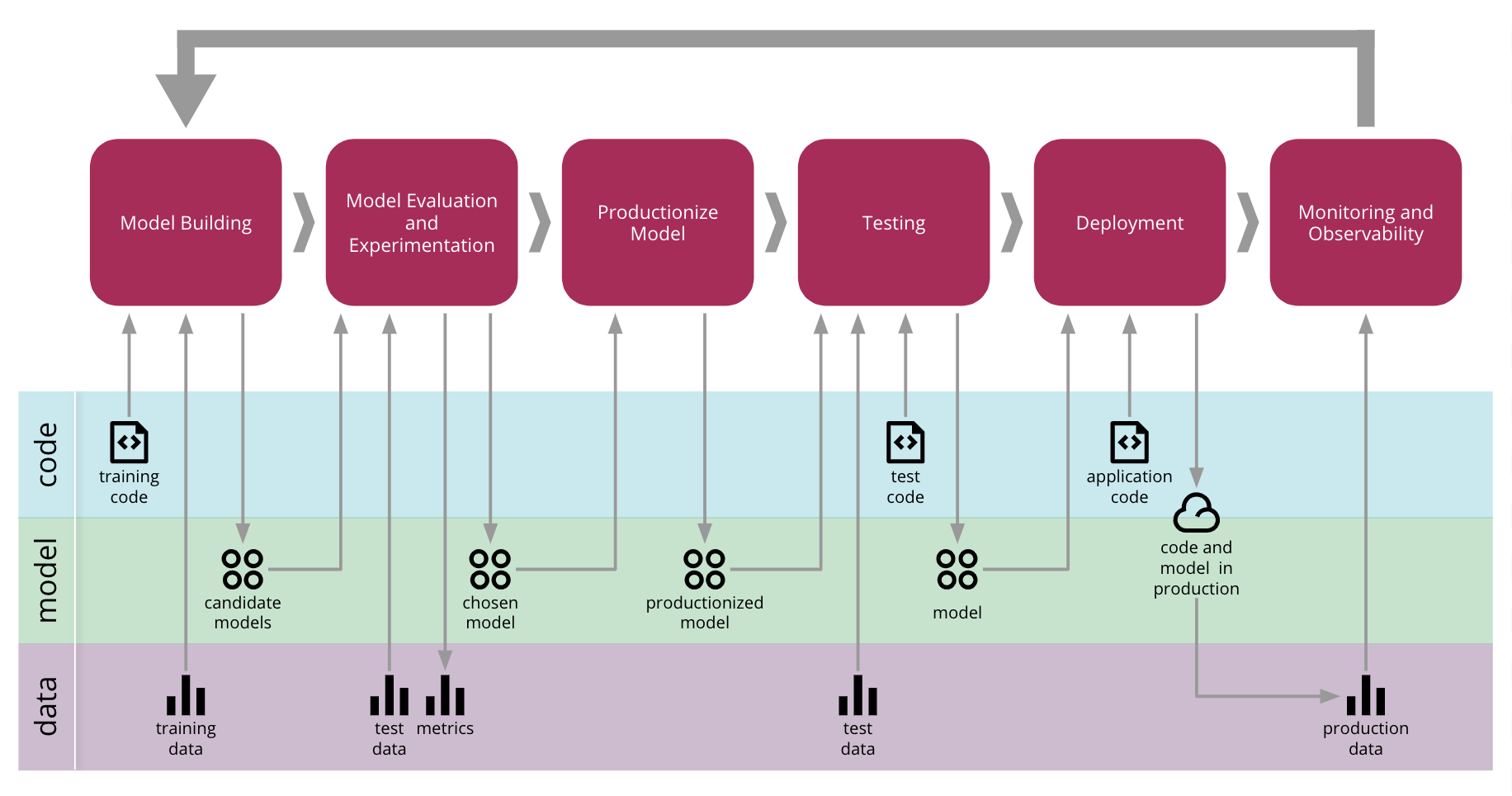
Full view of an ML model creation pipeline
Example of a tool we will use once we start training more of our own models.
Most of our models will be simple Python Pickle files that are loadable via Scikit-learn
Example Youtube Video Processing Steps